An introduction to tagged PDF files: internals and the challenges of accessibility
Update: January 2026
Please see Overleaf's instructions on creating tagged PDFs.
The LaTeX team has released new features that enable automatic PDF tagging, the central requirement for PDF accessibility. These new features are available in Overleaf in TeX Live 2025, with more recent updates available in the rolling TeX Live release available through Overleaf Labs.
It is now possible to produce a tagged PDF from LaTeX source that is conformant with WCAG 2.1 Level AA by following our user docs using TeX Live releases available in Overleaf.
The article below from 2020, while not updated with the latest information on LaTeX accessibility, can continue to be read for interest and for background information on PDF tagging.
What does this article cover?
This goal of this article is to provide an introduction to tagged PDF together with an overview of some technical challenges faced by software, including TeX engines and LaTeX, which aims to produce tagged and accessible PDF files. Accessibility, particularly of PDFs, is a broad and complex topic, which also has technical challenges that don’t always have a single, universally agreed or accepted solution—such as how to represent complex mathematics within PDFs in an accessible way: using MathML or LaTeX code?
Although we cannot take a deep dive into every topic, and have to simplify many details, we can take a look inside PDFs to show what tagging a PDF really involves. Overleaf hopes this article will serve as a useful introduction, providing sufficient background to enable readers to better understand the technical challenges and support their further reading and exploration of tagged PDF and accessibility. Resources within this article include:
- an 8-minute video exploring a tagged PDF produced by LaTeX;
- an Overleaf project to explore the use of space characters in LuaTeX;
- sound recordings demonstrating PDF accessibility issues.
Introduction
Ensuring accessibility of digital content is rightfully recognized as an important aspect of content production and dissemination. Furthermore, governments, including the United Kingdom and the United States, are passing laws which require content produced under their jurisdiction to comply with defined accessibility criteria. Compliance via dissemination of content in HTML is not unduly onerous, but ensuring the requisite level of accessibility for documents distributed in PDF format can be a significant technical challenge—depending on the software used to author content destined for output as a PDF file.
PDF emerged in the early 1990s as a solution to problems surrounding reliable document-transfer and history has shown it to be wildly successful. However, PDF is also a complex file format which arose prior to widespread recognition and acceptance of the need to facilitate accessibility of document content. Nevertheless, over time the PDF specification has evolved to provide features which enable and support the production of accessible PDF documents using a “stylized” flavour of PDF which Adobe calls tagged PDF.
In practice, the production of tagged—and fully accessible—PDF files places significant additional technical requirements upon software which outputs PDF—and that includes TeX engines and the LaTeX ecosystem of macros and add-on LaTeX packages.
Genesis of PDF as final-form digital paper
The genesis of Portable Document Format (PDF) heralds from an era in which transfer of documents between computers was fraught with difficulties, often caused by file conversions resulting in page reflow and other discrepancies compounded by incompatible fonts and text encodings used on different operating systems (notably Windows and Macintosh). This document’s author was working in publishing at that time and has vivid memories of dealing with those challenges!
PDF was designed to address file-sharing problems through the introduction of a universal, final-form (non-editable) digital paper, allowing for seamless transfer of self-contained documents which carried the fonts required to display them. Users could finally transfer all sorts of documents with reasonable certainty that recipients, irrespective of computer platform, could open and read them—document fidelity was preserved and messy page reflows, font compatibility/availability was a thing of the past.
Digital paper: good for all users?
The ancestry of PDF, as a form of digital paper, naturally assumed use of printed page numbers, typography or design elements as cues for visual navigation of its content—on screen or on paper. However, those visual cues/mechanisms are, of course, meaningless to people with severe visual impairment. Today, improved accessibility of digital content is rightfully recognized as an important aspect of content production and dissemination. The challenge for PDF was to provide mechanisms which facilitate non-visual access to content locked within a “container” originally designed to replicate the visual medium of the printed page.
The first version of the PDF specification (PDF 1.0) was officially released on June 15, 1993 followed by new versions with updates that, in 2001 (PDF 1.4), included the introduction of “tagged PDF” which “...enabled users of assistive technologies”. Subsequent releases of the PDF specification have extended and enhanced the features of PDF, culminating in the latest release (PDF 2.0) which, based on reports, has significantly overhauled accessibility features—although PDF 2.0 is not yet well supported by TeX engines.
Content inside PDFs
To appreciate the issues involved it’s worth examining how PDF files actually represent the page content they contain. Deep within a PDF file, the content for each page resides in that page’s content stream: a sequence of PDF operators (“commands”) which place text or graphics at a particular page location for rendering (display) by software being used to view the PDF. In effect, the content stream provides a graphical description or “recipe” which tells PDF-viewing applications how to “draw” each page—defining what is to be displayed on the page, and where. Naturally, that series of operators includes instructions to choose particular fonts at a specific size, select colours, define line widths, draw lines, curves and so forth—everything required to provide a complete graphical description for visual presentation of a page.
To reduce file size, PDF content streams are compressed and stored in a compact binary format but if you have access to suitable software, such as Adobe Acrobat Pro DC, you can use that to view a “decompressed” plain text version of page content streams.
Let’s consider how PDF operators might “draw” a table: the PDF content stream would contain an appropriate sequence of operators to produce horizontal/vertical lines, select different fonts and output text placed at various page locations to produce the content of the table. To demonstrate this, let’s consider a very simple untagged PDF document containing nothing more than a basic table with some text—created in Microsoft Word for reasons that will become evident later in the article. Here’s a screenshot displaying our simple PDF:
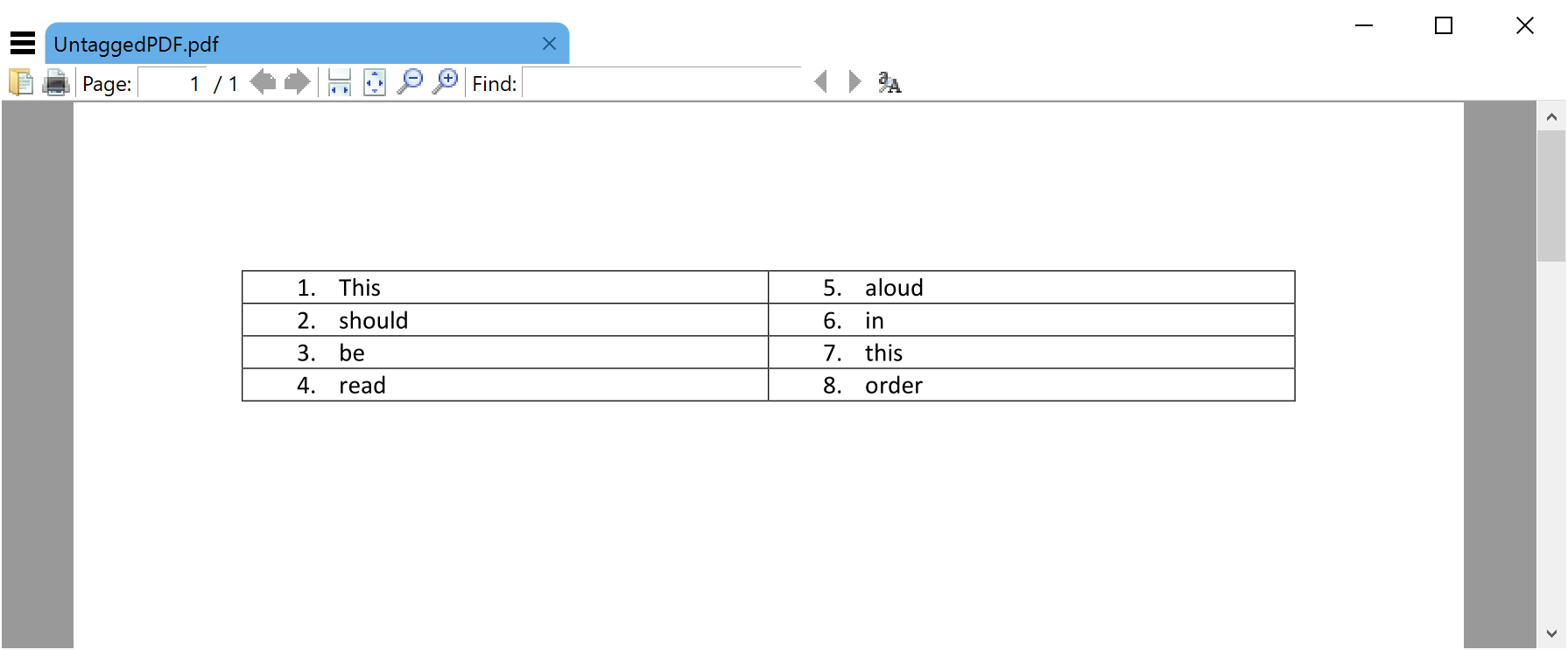
If we extract the (decompressed) page content stream for this file and paste the first few lines into a text editor we can summarize some of the PDF operators to get a “flavour” of how PDF files “describe” the content displayed on this page.
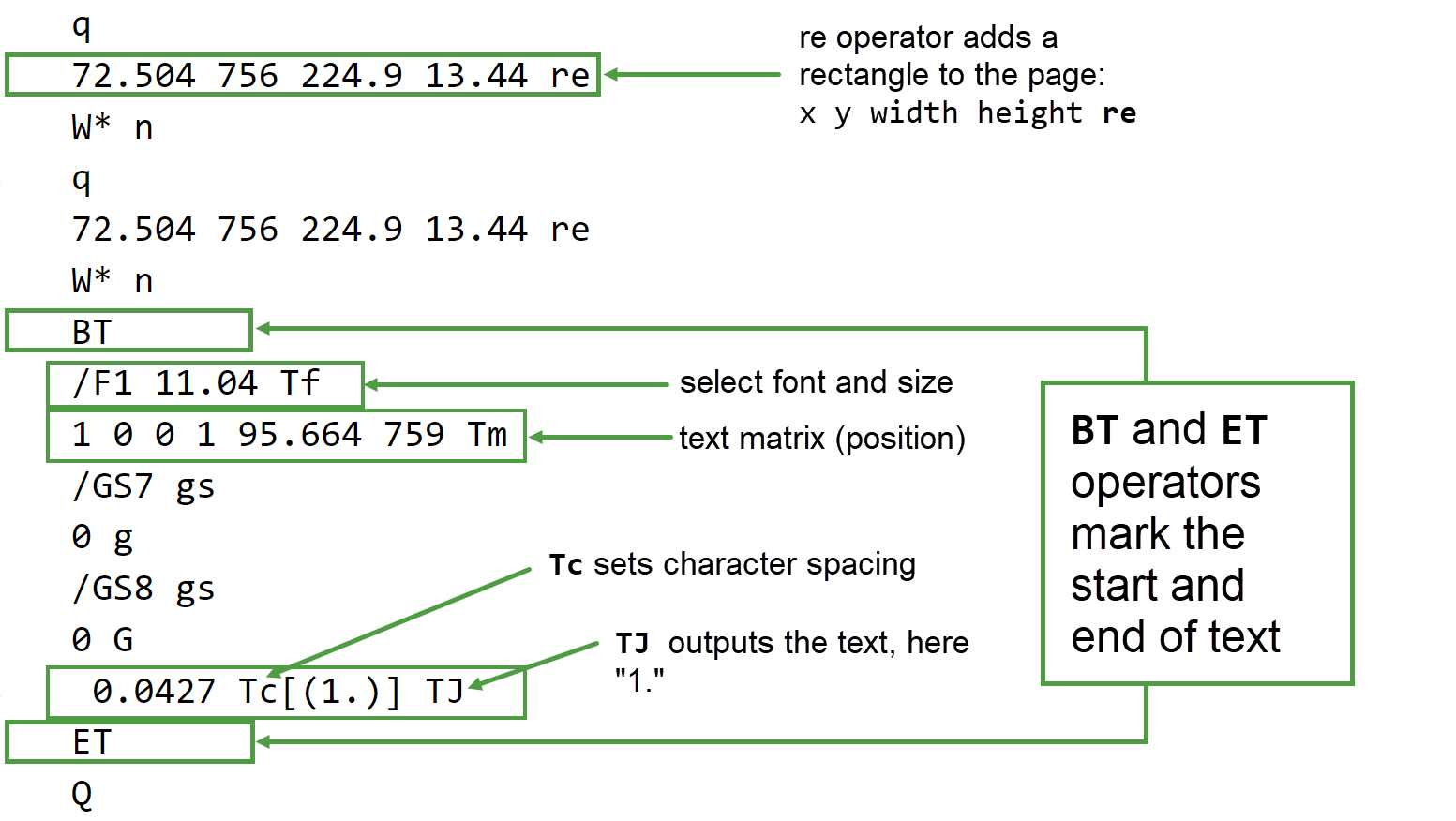
If you have access to Adobe Acrobat Pro DC you can use it to list the operators contained in a PDF page content stream. Here’s Acrobat’s Internal PDF structure view of the same PDF which helpfully provides a one-line description of every operator used to “draw” our single page containing a basic table—note these short descriptions are provided by Adobe Acrobat Pro DC, they are not present in the PDF file itself:
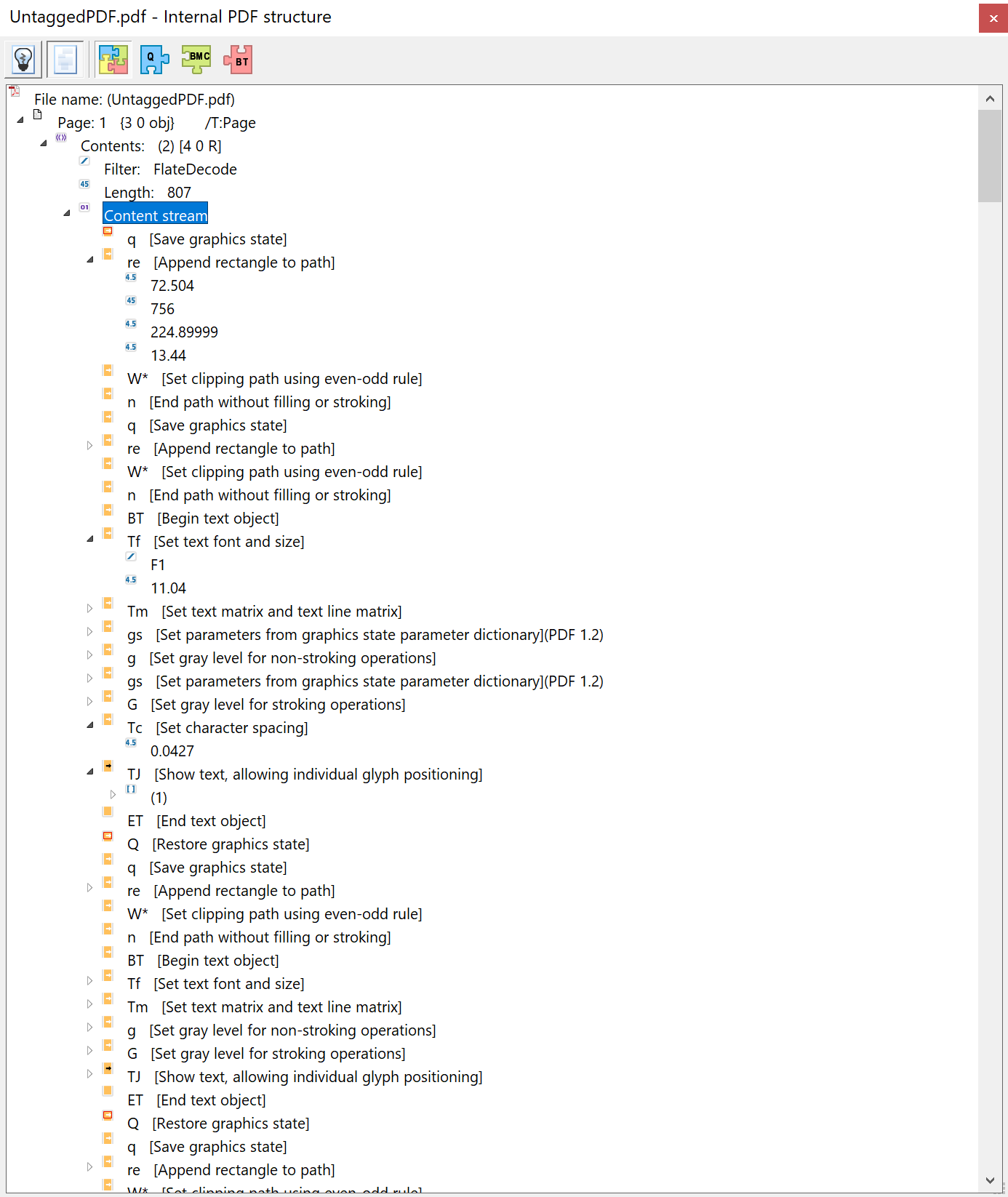
However, observe that none of those drawing instructions (operators) store any “meaning” or “description” of what they are actually producing: they are just a set of graphics operators which result in the construction of what a sighted observer recognizes as a table. Clearly, for those with severe visual impairment, displaying the table which results from those graphical operators in the PDF’s content stream is not a viable method for accessing that content. What’s required is a mechanism for PDF files to contain a suitable non-visual (machine readable) description of that table—and, of course, all other content items contained within the pages inside a PDF file.
To enable non-visual access to content, PDF files need to contain additional data which attaches “meaning” or semantics to collections or groups of operators being used to “draw” a particular piece of content. Necessarily, this principle of assigning or providing “meaning” has to extend to all forms of content contained in a PDF: that mechanism exists and is called tagging the PDF to produce a “variant” of PDF called, unsurprisingly, tagged PDF.
Introducing tagged PDF
Tagged PDF is the name given to a specific type of PDF file which contains additional data (and data structures) not present within untagged PDF files. Although the principles/ideas behind tagged PDF are amenable to an outline description, the full details are complex and occupy many pages in the formal PDF specification.
Adobe designed tagged PDF to achieve a number objectives which included making content accessible to users with visual impairments but it also encompasses the following list taken from Section 10.7 of Adobe’s PDF 1.7 specification:
- simple extraction of text and graphics for pasting into other applications;
- automatic reflow of text and associated graphics to fit a page of a different size than was assumed for the original layout;
- processing text for such purposes as searching, indexing, and spell-checking;
- conversion to other common file formats (such as HTML, XML, and RTF) with document structure and basic styling information preserved.
In addition, tagged PDF also requires:
- text within PDF content to be represented in a form that can be converted to Unicode;
- word breaks must be represented explicitly—note that TeX engines do not use space characters to separate words, they use TeX’s flexible spacing called glue (see below);
- actual (“real”) content is distinguished from artifacts of layout and pagination.
Underlying tagged PDF are two key concepts that we’ll review:
- defining the logical structure of content in a PDF file;
- markup (tagging) of PDF content with a set of standard content types.
Logical structure
Within longer documents, content is usually partitioned into a sequence of smaller content items; for example, books are typically broken into chapters which are themselves divided into sections and subsections containing paragraphs, tables, figure/charts, bulleted or numbered lists, footnotes and references and so forth. The structure and organization of content in such a book, or any other document type, is referred to as its logical structure.
The notion of a document’s logical structure plays an important role in accessibility of PDFs but, as a concept, logical structure can seem a bit vague and tricky to understand. The following definition from the Encyclopedia of Database Systems provides helpful insight:
“Logical structure refers to the way information in a document is organized; it defines the hierarchy of information and the relation between different parts of the document. Logical structure indicates how a document is built, as opposed to what a document contains.”
Note this definition of logical structure makes no reference to precisely how that structural information is physically stored; merely that it provides a representation of a document’s structure and organization. The precise details of how a document’s logical structure is stored or represented is implementation-dependent: a function of the software used to generate and process it.
Logical structure in PDFs
The PDF specification provides mechanisms through which the logical structure of a document can be recorded inside a PDF file—for use by software which, for example, might want to export the PDF’s content to other formats such as XML, HTML or Microsoft Word. Those export processes need to produce a correctly structured text document which conforms to the rules of the target export file format—that can be best achieved when the export processing is guided by logical structure information provided within the PDF.
Additionally, the logical structure of a PDF file is essential to accessibility software which, for example, might want to perform text-to-speech operations, reading content aloud to someone with visual impairments. The text-to-speech process needs to ensure content is being read-aloud in the correct order/sequence, otherwise it would produce nonsensical results. Note too that the very concept of a page may make no meaningful sense to accessibility applications that are only interested in the PDF’s content and structure of the document, not the visual partitioning and presentation into page-sized chunks.
Naming content items
Recording (storing) the logical structure of a PDF document requires some set of meaningful names assigned to the various types of content item likely to be found as part of a typical PDF document—identifying sections of content that represent headings, paragraphs, tables, lists and so forth. In addition, some content items such as table of contents, numbered/bulleted lists and tabular material have quite complex structures of their own so there also needs to be some guidances/rules to specify how those more complex contents items are constructed—their sub-structure. A further requirement is to clearly identify any PDF content that should be ignored by assistive software processing the PDF; for example, page headers and footers are pagination artifacts containing text that is superfluous to those with severe visual impairments: that content should be ignored.
The mechanisms used by PDF to define a document’s logical structure are designed to be flexible, so, in principle, different applications which generate and process PDF files could use names for content types using any convention of their choice. However, in order to maximize document interchange, allowing different PDF-processing applications to provide consistent results, Adobe defined a set of standard names for types of content items that PDF-generation software should adhere to. Within the PDF specification those standard names are referred to as tags, giving rise to the notion of tagged PDF.
Markup of PDF content: A peek “under the hood”
To make the discussion a little less abstract we’ll have a brief look at the internals of tagged PDF files—although we can’t cover all the details because tagged PDF is such a large, complex topic.
Marked content sequences: building blocks for tagged PDF
At the lowest level, the process of recording the meaning of content contained within a PDF page (i.e., within its content stream) begins with marked content sequences which are used to identify (give “meaning” to) clusters or groups of PDF operators. Marked content sequences are assigned a numeric identifier called its MCID (marked content identifier) which is an integer that runs from 0 to some maximum N on each page. Those MCID values provide a way to uniquely identify sequences of operators contained within the content stream of a particular page. To clarify, for every page the MCID identifiers start at 0 and increase sequentially up to some maximum value which depends on how many marked content sequences are contained within a particular page’s content stream.
Marked content sequences are, in effect, fundamental “building blocks” which are used to assemble higher-level data structures called structure elements. Those structure elements contain a tag, which is the name used to identify which type of content item they represent.
Example of structure elements
Here we are jumping ahead slightly, but it’s worth reviewing an example. Suppose you have 3 small text fragments of page content and each one is identified in the content stream by a different marked content sequence. Each of those 3 text fragments can be packaged into its own structure element, with a tag, and all three can be “linked together” using another structure element to represent a higher-level content item such as a line in a table of contents.
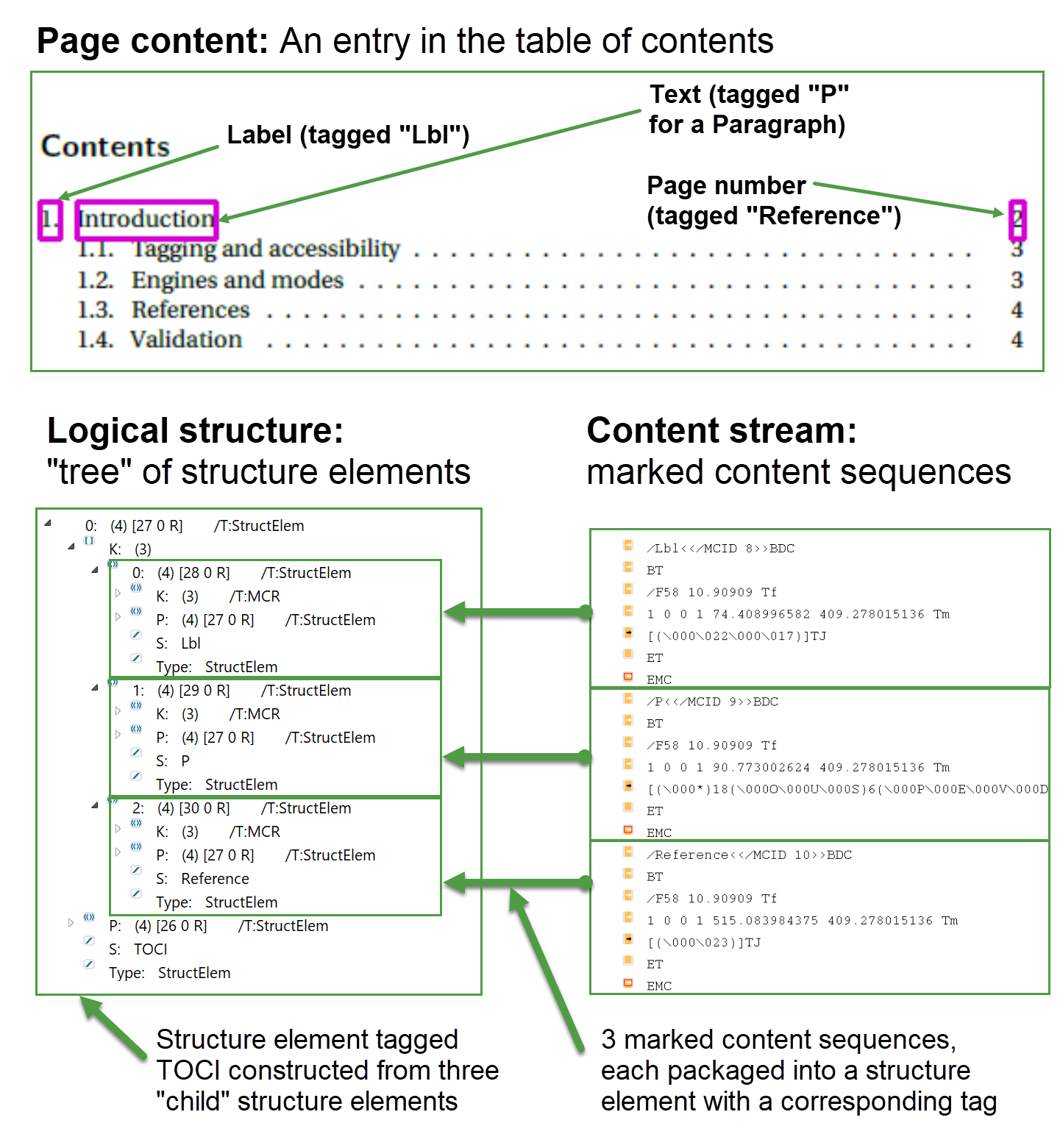
Through a form of parent–child data relationship, collections of structure elements are combined to create linked data structures that represent more complex data items such as numbered and bulleted lists, tables, mathematics and so forth. Ultimately, the entire collection of structure elements contained in the whole PDF file are further linked together and combined to create the logical structure of the PDF document—we will re-visit this later in the article.
What is a marked content sequence?
In the discussion above we used a simple untagged PDF document containing a table (created in Microsoft Word) but if we instruct Word to create a tagged PDF we can see that some additional markup has appeared in the page content stream. Here, we are only considering the first few lines of the content stream (there are hundreds of lines) but note the presence of additional operators such as /P <</MCID 0>> BDC and EMC which are used to identify a marked content sequence. We won’t explore the full syntax of marked content sequences but refer the reader to page 862 of Adobe’s official PDF 1.7 specification.

For easy reference, we again show the untagged version:
In the untagged PDF, operators such as /P <</MCID 0>> BDC and EMC are absent but the remaining operators are unchanged: the untagged PDF lacks the additional markup used to identify certain sequences/collections of operators. Again we can also use Adobe Acrobat’s Internal PDF structure feature to view the marked content sequences within a content stream—here, we have highlighted them using a green border:
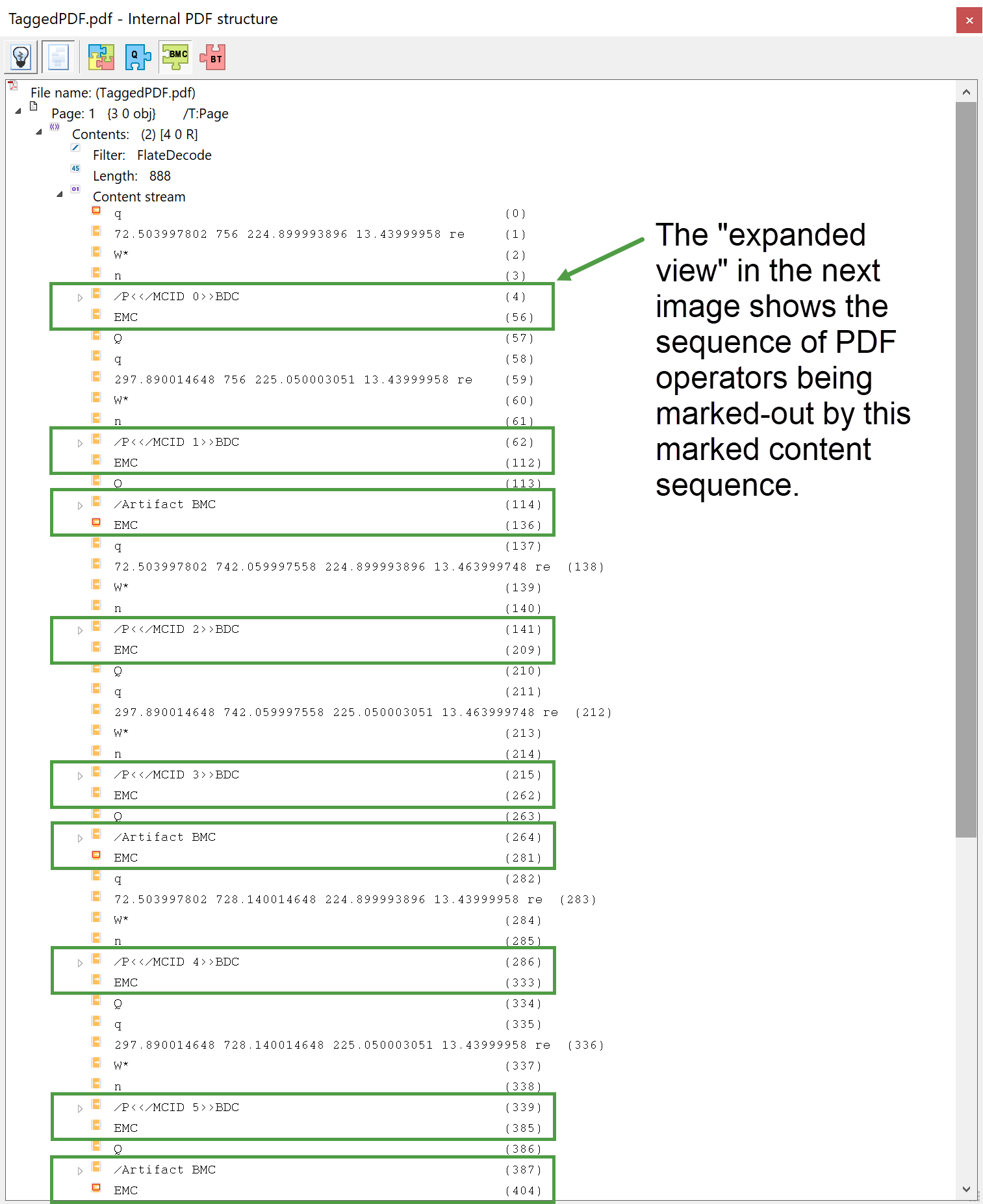
Note that some pieces of content are marked with /Artifact which identifies material on the PDF page that should be ignored by assistive software applications, such as those which read aloud to visually impaired people.
The following screenshot shows an expanded view of the first marked content sequence—the one with MCID value of 0. The end of the marked content sequence is identified by the PDF operator EMC.

Storing the logical structure
As noted, in addition to providing a description of individual content items (paragraphs, list, tables etc) it is necessary for accessible PDFs to contain a representation of the entire document in the form of its logical structure. Individual pieces of accessible content must be linked together to create a complete, navigable and accessible document—similar to how a single HTML document is constructed from paragraphs, graphics, tables to create a web page. Furthermore, it is essential that a PDF document’s logical structure ensures that all content can be navigated in the correct reading order, independent of the order in which the page content was written out to the PDF page content streams. We’ll explore reading order in more detail below.
Logical structure: a “tree” of structure elements
We noted that PDFs use something called a structure element to represent individual content items, and that a structure element contains a tag to identify which content type it represents. To provide a representation of the document’s logical structure all structure elements are linked together, using parent—child relationships, and organized into a “structure tree”. Internally, tagged PDF files contain an object called the StructTreeRoot which contains (points to) structure elements which act as the starting point or “root” of the document's logical structure tree. Usually, the “root” of the structure tree starts with a single structure element that is tagged Document which contains numerous child structure elements that, collectively, represent the entire content of the document. Any software designed to produce accessible PDFs via tagging has to build this very complex data structure (and others!)—and that includes TeX engines and LaTeX.
An example of such a document structure tree (StructTreeRoot) is shown in the following screenshot of a tagged PDF open in Adobe Acrobat Pro DC:
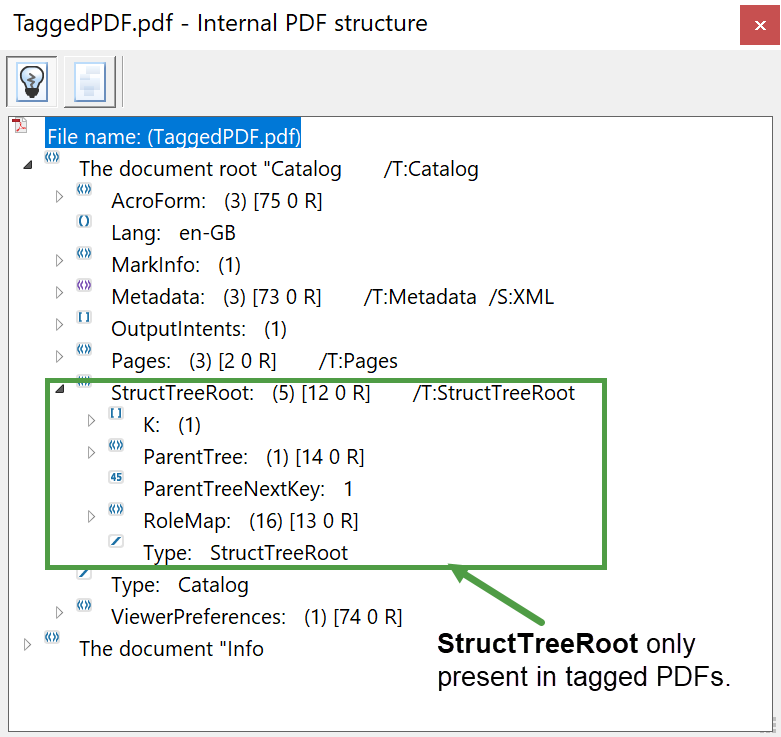
Compare the above structure to the untagged PDF version:
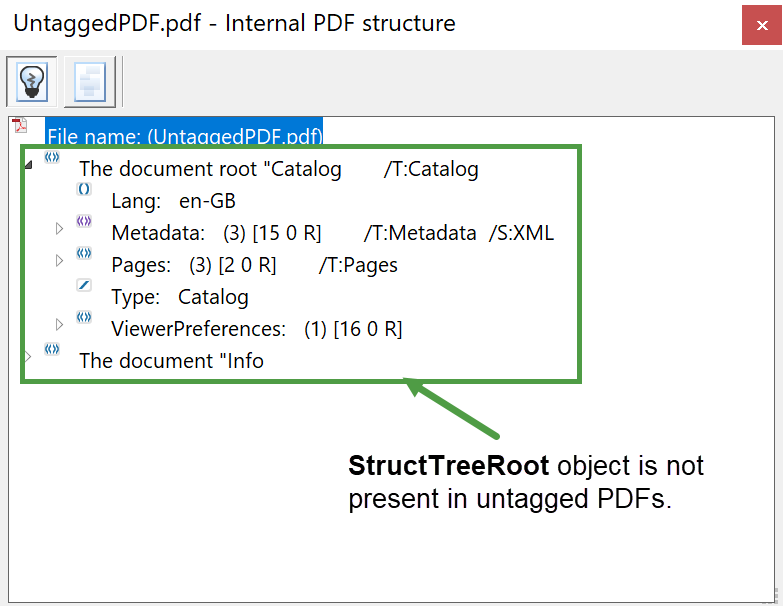
Exploring the logical structure of PDFs
We start with some graphics to summarize what we have covered and conclude with a video that uses Adobe Acrobat Pro DC to show more detail of the logical structure of a tagged PDF file. Firstly, we start with a schematic to show the general principles: a PDF page with its content stream marked-up with marked content sequences (MCS).

Those MCS are subsequently combined into structure elements which form the basis for larger content types which are themselves further linked together to store the PDF’s logical structure within an object called StructTreeRoot.

Video showing the logical structure of a tagged PDF
The following video (8 minutes) uses Adobe Acrobat Pro DC to take you on a “guided tour” to explore details of the logical structure of a tagged PDF file produced using LaTeX. The tagged PDF file used in the video is called tagpdf.pdf, which is an excellent example containing documentation for the experimental LaTeX package tagpdf. The aim of the tagpdf package is to provide “tools to experiment with tagging and accessibility using pdfLaTeX and LuaTeX”.
A note on tagging and flexibility
The HTML specification provides a large number of predefined tags for use in constructing web pages, but it also allows flexibility in how you combine them to create your chosen HTML document. Similarly, Adobe’s tagged PDF specification provides a set of predefined tag names but imposes very few restrictions on how you combine those tags to represent complex content items within a PDF—by design, there is a great deal of flexibility. In addition, with any specification as large and complex as PDF, it is inevitable for some ambiguities, or issues of clarity, to creep into the written specification. Software developers tasked with implementing such a complex specification may have to make “judgement calls” when interpreting it because they are faced with converting written descriptions into working code.
The inherent flexibility of tagged PDF together with interpretation of specifications (or accessibility standards) naturally impacts developers of document-authoring applications: which combinations of tags should be used to represent user-created content when outputting it to a tagged PDF file? If you factor in the limitless ability of users to construct all sorts of content by utilizing features of the document-authoring software then you can see that automated production of accessible tagged PDFs is something of a challenge!
Perhaps reflecting the unavoidable complexities of producing tagged PDFs which fully conform to accessibility standards, the web is replete with “how to’s”, “tips” and “best practice” advice on creating tagged PDFs via software such as Adobe InDesign or Microsoft Word. In addition, the PDF Association has produced a useful document called Tagged PDF Best Practice Guide written to assist developers facing the challenges of implementing tagged PDF and PDF/UA.
Got a PDF but is it accessible?
To determine whether a given PDF file complies with required accessibility standards such as PDF/A or PDF/UA (see below) it has to be validated using an agreed validation process or software tool. However, validation usually takes place after the document is finished, but that process might not be conducted by the document’s author but by accessibility specialists within the organization or body who requested compliance. If the PDF fails validation then it might need skilled manual intervention via Adobe Acrobat Pro DC to fix the tagging (if possible). Alternatively, it might even have to go back to the author to amend their original document, possibly by avoiding use of the authoring software features which caused the problems—which could be extremely difficult to achieve because it may be beyond the author’s control.
Reading order and content order
As noted, production of truly accessible PDFs places additional technical requirements on the authoring software and, potentially, on document authors too by enforcing “authorship discipline” in how they use/apply features of the authoring software. Although tagged PDF is the mechanism which enables the production of fully-accessible PDFs, just because a PDF is tagged does not automatically mean it is fully accessible, as we’ll see in an example below.
To produce fully accessible PDFs, all content items in the PDF should be tagged to create a logical structure which ensures content can be accessed and read in the correct sequence—called the reading order. This may appear to be “obvious” but when software writes out a PDF file it can output graphics and text to the page content streams in any order it chooses. For example, suppose a page started with some text, followed by a table and concludes with a graphic, giving a natural reading order of:
- text
- table
- graphic
When written to a PDF, software generating a content stream for that page could start with operators to draw the table, then output operators to produce the graphic followed by operators for the text, which would, in the content stream, produce a content order of:
- table
- graphic
- text
Of course, everything will be placed at the correct position when that page is viewed. To a fully-sighted reader, the order in which those items are stored inside the page’s content stream is of no interest: they experience a complete rendered page with everything in the correct location.
However, if assistive software had to rely on the ordering of items in a content stream (the content order) it would face difficulties if the content order was different to the natural reading order; for example, tools for reading aloud would read out material in the wrong sequence. Fortunately, assistive software can use a tagged PDF’s logical order (structure) which must be organized to reflect the sequence in which content should be read. It is for these reasons that data representing the document’s logical structure is stored separately from the actual content displayed on the visible pages, to allow
“... the ordering and nesting of logical content elements to be entirely independent of the order and location of graphics objects on the document’s pages.” (page 856 of The PDF Reference, sixth edition, November 2006)
In practice, guaranteeing a logical order which preserves reading order is far more challenging than it might appear, so let’s use a simple, albeit fabricated, example which gives an indication of the issues involved.
Incorrect reading order: An example using Microsoft Word
A document’s author might use the features of their chosen authoring software to achieve a specific visual effect—such as using tables to create a particular text layout. For example, the following screenshot shows the Microsoft Word document used in previous examples. It contains a table which has been used to create a set of side-by-side numbered paragraphs. But when it comes to tagging this content, how should it be treated: tagged as a table or a numbered list? Both of those content types require a complex tagging structure to represent them correctly. In the following image, note the order in which the numbered paragraphs are intended to be read: column-by-column, not row-by-row.
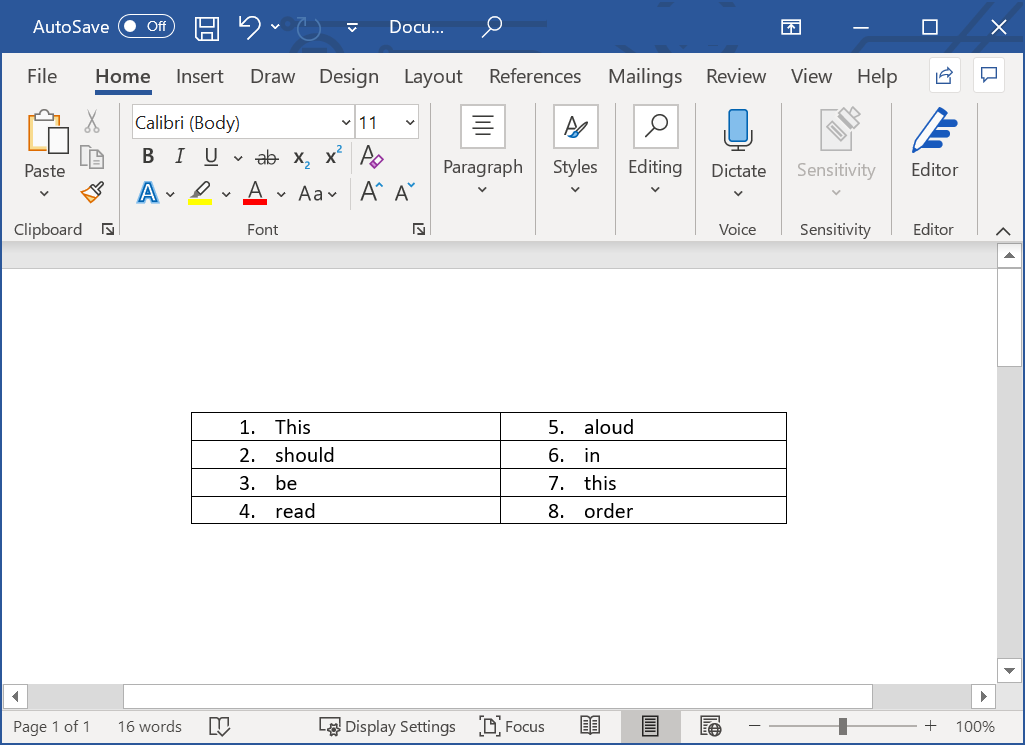
If we ask Word to save this document to a PDF using its built-in export—not the Acrobat PDFMaker plugin—we can tell it to create tagged PDF:
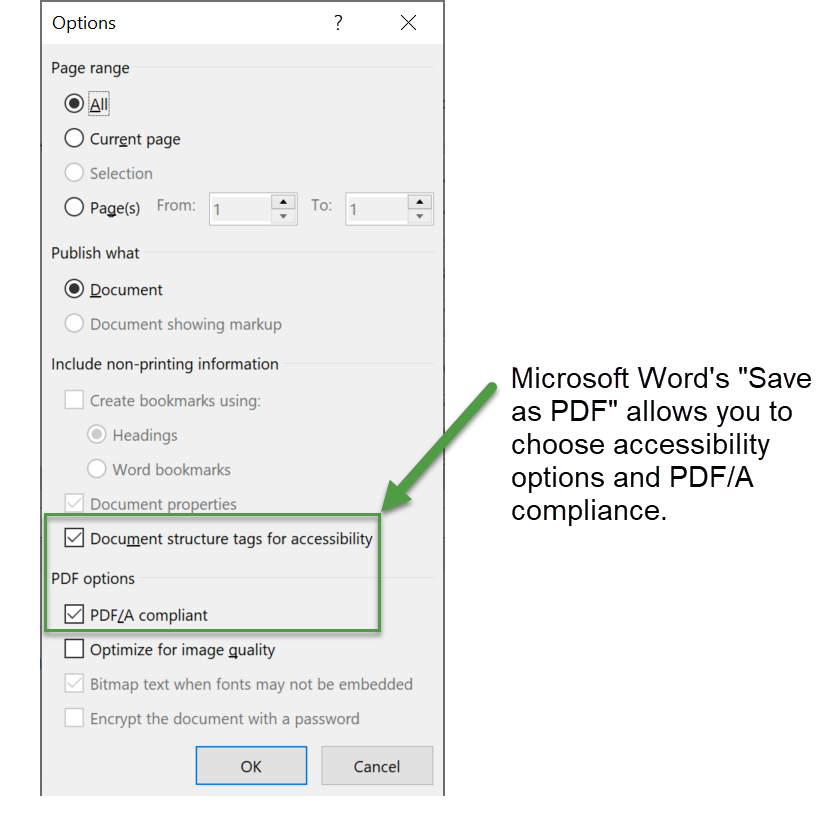
So, how does Word tag this layout? In the following very short video (14 seconds) we use Adobe Acrobat Pro DC to inspect the tagging structure produced by Microsoft Word.
For this document, Word has created a tagged PDF document which uses a Table tag containing two sub-tags: THead for the table header row group and and TBody to represent the group of rows for the table body. THead and TBody both contain TR tags to represent individual rows of content. The TR tags contain further tags to represent the numbered list item present in each cell. The following screen image shows the deeply nested tagging structure and the correspondingly complex logical structure needed to represent even this extremely basic document!
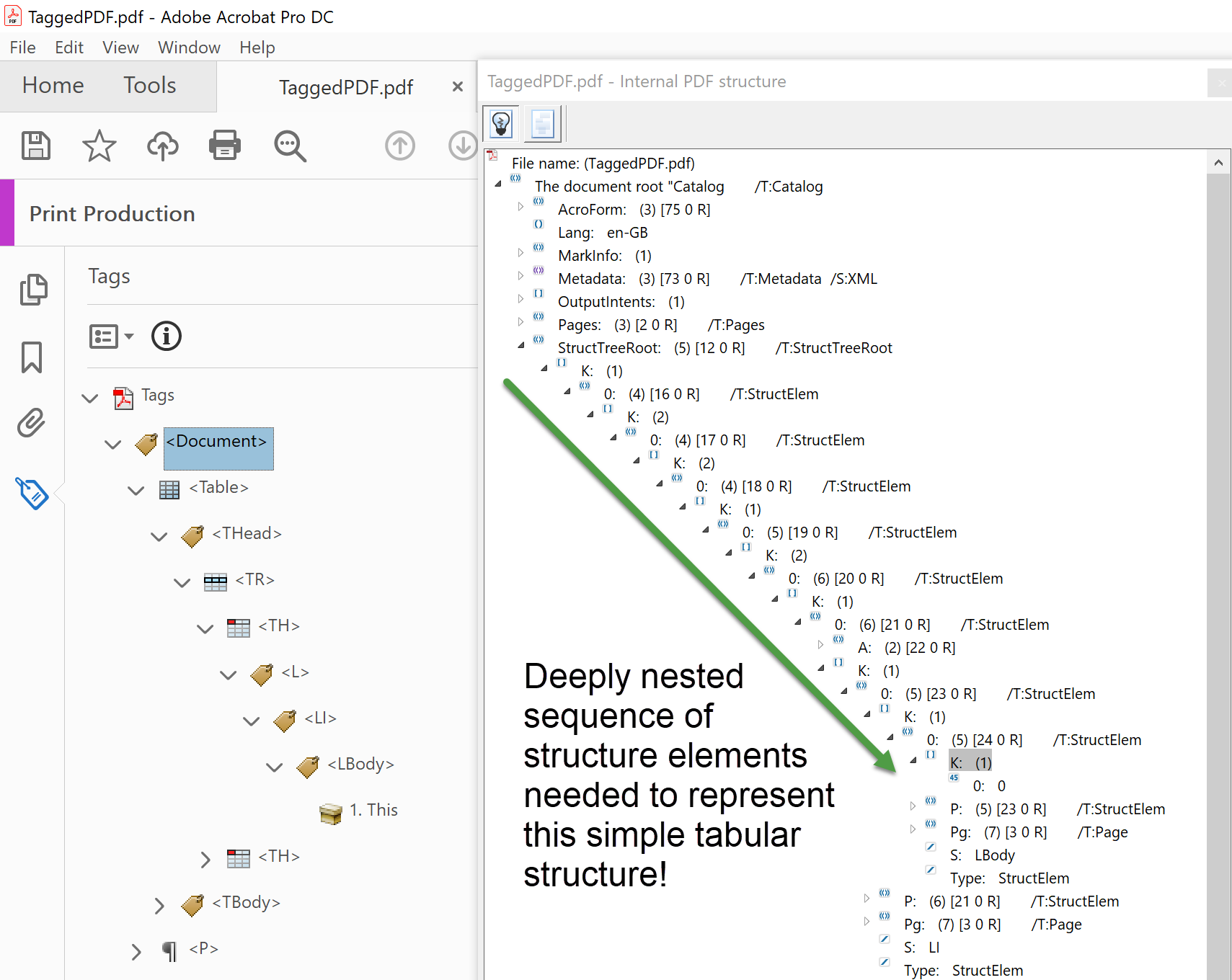
Compared to PDFs generated by TeX and LaTeX, this Word example is an extremely simple document, but it still requires a complex logical structure to represent it. Imagine the level of tagging complexity required to represent LaTeX-generated PDFs containing complex mathematics and tables!
Tagged, yes, but the reading order is incorrect
Even though Word does produce a tagged PDF it demonstrates one of the fundamental challenges faced by any application trying to produce fully accessible PDFs: correctly representing the intended reading order of the content. During creation of the tagged PDF, Word’s internal processes decided to write the corresponding content stream by outputting the table on a row-by-row basis, not column-by-column. To a fully-sighted reader viewing the PDF, these low-level details make no difference: the table displays correctly. However, for visually impared people, Word’s logical document structure produces the wrong result because the desired reading order (column-by-column) is not preserved: the content is read aloud in the wrong order.
The following audio recording was produced using Adobe Reader DC’s “Read Out Loud” feature. As is evident, the text is read out in the wrong sequence: row-by-row, not column by-column:

As noted above, this example is somewhat contrived but it does demonstrate just how easy it is to apply combinations of software features which trigger accessibility problems—but how is the document author expected to know this in advance? It is likely that this issue would only be detected if the resulting PDF underwent practical accessibility usage tests—e.g., by using assistive software. Potentially, such documents could pass PDF/A compliance/validation tests but fail in “real world” usage. Ensuring the correct reading order of a PDF file such as this would require skilled manual intervention using advanced PDF editing tools such as Adobe Acrobat Pro DC: a time-consuming and expensive process. Alternatively, the document’s author could refrain from using this particular form of content expression or layout—but only if they knew it was problematic!
Using space characters to separate words
As you type text into word processors or text editors you use the space character to mark the end of one word and the start of the next. If you subsequently create a PDF from such a document the space characters you typed will of course be output and form part of the text stored in the PDF. However, TeX engines do not use space characters to separate words in typeset text; instead, they convert space characters into a form of flexible spacing called glue (see this Overleaf article for more information on TeX boxes and glue).
Within the content stream of PDF pages created by TeX engines, the separation of individual words is achieved by moving to a different position on the page and starting the text for the next word—rather than outputting a space character to achieve that spacing. Furthermore, the amount of space between words in paragraphs of text typeset by TeX engines varies from line-to-line due to TeX’s linebreaking algorithm. That variation is reflected in the positional data written out to the content stream of PDF pages.
This aspect of TeX’s typesetting has implications for copying/pasting text from its PDFs and for assistive software trying to read aloud the typeset text in PDFs produced by TeX engines. Assistive software has to parse the content stream of a PDF page to extract the text it needs to process. Clearly, such software needs some mechanism to detect the start and end of words—the most obvious solution is to use a space character. With that in mind, accessibility standards require individual words to be clearly terminated (e.g., by space characters) which is problematic for TeX engines due to their use of interword glue.
But all is not lost!
In 2014 pdfTeX introduced 2 new primitives to improve accessibility support by enabling the use of space characters between words in the PDFs it outputs:
\pdfinterwordspaceon\pdfinterwordspaceoff
These commands make use of a “dummy font” containing just a space glyph. Details and an example can be found on page 29 of the pdfTeX User Manual.
Using LuaTeX: An example in the Overleaf Gallery
LuaTeX does not support those pdfTeX primitives but it can be programmed to achieve results very similar to pdfTeX using LuaTeX’s so-called callback mechanism. An Overleaf project to convert glue to space characters is available in the Overleaf Gallery under the title Using LuaTeX to convert interword glue to spaces and kerns.
If you typeset your LaTeX code using LuaTeX (i.e., the LuaLaTeX compiler option on Overleaf) then, by using Lua code, you can post-process a typeset paragraph to find any interword glue and replace it with a space character plus a suitable kern. The spacing provided by the width of the space character can be added to (or reduced) by calculating an appropriate kern value to preserve the amount of space provided by the interword glue, resulting in no visual difference to the typeset result.
To understand the difference this makes for users of accessibility software, listen to this sound recording captured from Adobe Reader DC’s Read Out Loud feature. It records the two lines of text in that project being read out loud, before and after converting glue to spaces. Notice how the second reading of the line, which uses spaces, is read aloud quickly and fluidly compared to the line using interword glue.
The Overleaf project is a plain TeX file compiled using LuaTeX and provided for experimental use only; it is not intended to be a full, production-quality solution. Primarily, it is designed to assist with understanding technical issues related to accessible PDFs. The Lua code used in that project is based on work contained in a much earlier Overleaf article Boxes and Glue: A Brief, but Visual, Introduction Using LuaTeX.
Note: For simplicity the project uses its own very minimal OpenType font loader derived from this code: http://wiki.luatex.org/index.php/Use_a_TrueType_font.
Other accessibility issues and tagged PDF
Although tagging allows identification of content items present within a PDF, some types of content, such as graphics or complex mathematics, require additional data or information if they are to be made accessible via software designed to support visually impaired people. To provide and support accessibility for a wide range of content types, the PDF specification provides the ability to attach “Alternate Descriptions” or “ActualText” to content items, providing suitable textual descriptions or other machine-readable representations. For example, MathML has been designated for this purpose within the PDF 2.0 specification.
Is it “real content” or just an artifact?
For people who are visually impared, the process of partitioning and displaying content in rectangular page-sized chunks has unwanted side-effects, such as word hyphenation. Furthermore, apects of page design or layout used to enhance visual presentation are quite meaningless to those who cannot see it. For these reasons, tagging PDF content has to recognize that some content within a PDF should be treated as an artifact of visual presentation or pagination. For example, page numbers, page headers and footers, shaded backgrounds or other design cues need to be identified so that accessibility software processing the content knows to ignore them.
Overview of the PDF/A standards
Requests for producing accessible PDFs usually make reference to an ISO standard called ISO 19005, more commonly referred to as PDF/A. However, because PDF/A is a family of standards, simply requesting “PDF/A conformance” might not fully specify the actual requirements. To see why, let’s start with a short outline of PDF/A from the PDF Association website (accessed 21 May 2020) which describes ISO 19005 (PDF/A) as follows:
“The primary purpose of ISO 19005 is to define a file format based on PDF, known as PDF/A, which provides a mechanism for representing electronic documents in a manner that preserves their static visual appearance over time, independent of the tools and systems used for creating, storing or rendering the files.
A secondary purpose of ISO 19005 is to define a framework for representing the logical structure and other semantic information of electronic documents within conforming files.
Another purpose of ISO 19005 is to provide a framework for recording the context and history of electronic documents in metadata within conforming files.”
Clearly, PDF/A has several core objectives.
Evolution and growth of PDF
The PDF 1.0 specification was published in 1993 and contained just 230 pages. However, 13 years later the specification for Adobe’s PDF version 1.7 is well in excess of 1000 pages! Over time, the size and complexity of the PDF specification has grown by adding to the supported feature-set: encompassing new technologies and the requirements of increasingly sophisticated PDF-based workflows and use-cases within different markets and communities. However, it’s likely that no user, or set of users, ever makes use of all the possibilities: PDF has to “cover all bases” to make sure it can service the needs of the widest possible market. For example, many PDF features designed to support high-end commercial printing are not required by typical day-to-day office usage as a format for storing or sharing documentation.
PDF/A: “back to basics” for PDF
The core objective of PDF/A is to ensure conforming PDFs are suitable for long-term archiving or contain content which is accessible to people using various assistive technologies to “consume” those PDFs. To achieve these goals PDF/A restricts the set of PDF features permitted in conforming PDF files, forbidding use of features that could compromise archivability or accessibility. You can think of PDF/A as a set of standards which specify how conforming PDF files use a subset of the full PDF specification to produce files that are suitable for long-term archiving or ensuring their content is accessible. PDF/A’s restrictions enable PDFs to be used as an “archival digital paper” which is independent of the PDF-reading technology and computing environment used to access their content. Conforming PDFs should not contain anything whose behaviour is “implementation dependent”—i.e., depends on the specific software or operating systems being used to view or process them. PDFs must also be complete: key document resources must be embedded in the file—such as fonts or colour profiles.
PDF/A versions and conformance levels
There are different versions of the PDF/A standard, each reflecting a particular version of the formal PDF specification (PDF 1.4, 1.7 and 2.0). In addition, there are various conformance levels that specify which aspect(s) of the PDF/A standard a PDF file conforms to. Consequently, when claiming or requiring “PDF/A conformance” you should think of PDF files that conform to
PDF/A-<version><conformance level>
For example
- PDF/A-1a: means PDF/A version 1, compliance level a
- PDF/A-2b: means PDF/A version 2, compliance level b
We explore these in a little more detail.
PDF/A versions
The PDF/A standard is under the auspices of the ISO, published as a standard called ISO 19005. As noted, the PDF specification has evolved over time and that, in turn, necessitated updates to ISO 19005, resulting in the table below:
| PDF/A version | ISO standard | Based on PDF version |
| PDF/A-1 | ISO 19005-1:2005 | PDF 1.4 |
| PDF/A-2 | ISO 19005-2:2011 | PDF 1.7 |
| PDF/A-3 | ISO 19005-3:2012 | IS0 32000-1 (PDF 1.7) |
At the time of writing (April/May 2020) an updated PDF/A-4 (ISO 19005-4) is in preparation.
PDF/A conformance levels
In addition to three PDF/A versions (PDF/A-1, PDF/A-2 and PDF/A-3) there are three conformance levels:
- Level A (accessible) for accessibility (includes archiving requirements of Level B)
- Level B (basic) for archiving
- Level U (Unicode) (= archiving plus using Unicode for text)
Here’s a short description of these conformance levels:
- Level B (basic) is the minimum requirement for compliance under PDF/A. It defines requirements to ensure conforming PDF documents are suitable for long-term archiving—that they can always be reliably viewed or printed independent of specific software, tools or operating systems.
- Level A (accessibility) includes the requirements of Level B conformance but, in addition, requires the use of tagged PDF to provide logical structure and reading order information together with the use of Unicode to enable access to the document’s text.
- Level U (Unicode) conformance was level added to PDF/A-2 and builds on Level B by additionally requiring the use of Unicode for document text but it doesn’t go as far as Level A by mandating structure information.
PDF/A versions and conformance levels can be summarized in a table:
| Conformance level | PDF/A-<version><conformance level> | ||
| Level A (accessible) | PDF/A-1a | PDF/A-2a | PDF/A-3a |
| Level B (basic) | PDF/A-1b | PDF/A-2b | PDF/A-3b |
| Level U (Unicode) | N/A (did not exist for PDF/A-1) | PDF/A-2u | PDF/A-3u |
PDF/UA (“Universal Accessibility”)
Although Level A compliance of the PDF/A standard goes some way to defining requirements for accessible PDFs, another ISO standard called ISO 14289, referred to as PDF/UA, goes further. PDF/UA strengthens accessibility requirements and clarifies guidance contained in the PDF/A standards and has become the preferred standard for accessible PDFs.
Matterhorn protocol
Readers with a deep interest to learn more about PDF/UA compliance may be interested in the Matterhorn Protocol which is “a list of all the possible ways to fail PDF/UA compliance”.
Validation software
To check if a PDF file conforms to a particular standard it has to be validated using compliance software which scans through the PDF to check whether its content and structure conform to requirements of that standard—such as PDF/UA or PDF/A-xa (where x = 1, 2 or 3). Note that validation of PDFs—processing them with a preferred validation tool—can produce diagnostic messages or warnings which can be quite cryptic to the non-expert user—perhaps due to some low-level PDF data (or structure) which fails to meet the relevant standard. For many authors, interpreting those warnings and converting them into an actionable fix to their document(s) can be quite a challenge.
Free validation software
- veraPDF which, to quote their website (accessed 28 May 2020), is a “purpose-built, open source, file-format validator covering all PDF/A parts and conformance levels”.
- (Windows only) PDF Accessibility Checker (PAC 2024) which is a “...free PDF accessibility checking tool that has been tried and tested since 2010”.
Commercial validation software
- Adobe Acrobat provides a suite of PDF validation tests together with tools to edit and fix-up tags in non-compliant PDF files.
PDF Association: a great source of information
The PDF Association produces many excellent resources on PDF/A, PDF/UA and many other PDF-related topics—including videos on their YouTube channel together with articles and free technical publications available on their website. One such publication is PDF/UA in a Nutshell which provides an invaluable introduction to the PDF/UA standard and its requirements.
Accessible PDFs from TeX engines and LaTeX
Hopefully, the preceding discussions have indicated that production of fully accessible and correctly tagged PDF files is a demanding technical challenge. Furthermore, even the simple Microsoft Word example demonstrated that authors can very easily use combinations of software features that result in tagged PDF documents which fail accessibility criteria.
As an authoring tool, LaTeX provides authors with near unlimited flexibility in the range and complexity of documents you can create—which may be the very reason for choosing it in the first place. LaTeX also supports extensibility via thousands of add-in packages that authors can use as part of their documents. On top of all that, authors have the freedom to write new TeX or LaTeX macros, or redefine existing ones, to achieve specific effects. However, perhaps this freedom and flexibility has a price because the content produced by the myriad interactions of all those LaTeX packages and macros “somehow” needs to be orchestrated if LaTeX is to automatically generate correctly tagged and accessible PDF output.
In practice, the extensibility, power, versatility and authoring “freedom” bestowed by LaTeX present technical challenges to seamless and transparent (“automatic”) production of fully accessible tagged PDF documents which conform to the PDF/UA or PDF/A-{1|2|3}a standards. The wider TeX and LaTeX community is trying hard to address those challenges and The TeX User Group (TUG) is coordinating research and development efforts through the PDF accessibility and PDF standards working group. There is a discussion list which provides a way for interested parties to discuss the production of tagged PDF files using TeX and LaTeX.
In these discussions it’s worth remembering that LaTeX is not actually an executable typesetting program, it is a large collection of sophisticated macros (commands) written in a lower-level language called TeX. Sitting between your carefully crafted LaTeX document and the final typeset PDF is a piece of software called a TeX engine whose job is to “execute” the collection of LaTeX commands (i.e., macros) used to write and construct your document—converting them into the typeset representation of your document saved as a PDF file. Those who are new to the TeX/LaTeX ecosystem are often, and understandably, bewildered by the plethora of cryptic-sounding names used for the tools they encounter: TeX, LaTeX, pdfTeX, pdfLaTeX, XeTeX, XeLaTeX, LuaTeX and LuaLaTeX. If you feel the same, help is at hand in the Overleaf article What’s in a Name: A Guide to the Many Flavours of TeX which explains the origin and meaning of all those terms.
TeX engines such as pdfTeX, XeTeX or LuaTeX are a class of software called document compilers: they take your LaTeX code and compile it into its typeset form by “converting” LaTeX macros (commands) back into their lower-level TeX language instructions which are “executed” to produce the typeset result. TeX-based typesetting systems are capable of producing exceptionally complex content—including advanced mathematics, music notation, chemical structures, graphics and sophisticated multilingual typeset text. To ensure those complex documents comply with accessibility standards and regulations, TeX engines, together with the LaTeX macro collection, and LaTeX packages, need to generate appropriately tagged PDF files by embedding a great deal of additional data into the PDF files they generate.
Although TeX engines can generate extremely complex PDF files, their internal processes, algorithms and functions do not have built-in features specifically designed to support the production of tagged and accessible PDFs. Instead, support for tagging and accessibility has to be achieved through complex macro programming which “injects” additional data into the PDFs generated by TeX engines—creating the marked content sequences, structure elements and logical structure data structures stored in StructTreeRoot. And here is where that “orchestration” comes into sharp focus: code within the core (kernel) of LaTeX together with code in thousands of packages and countless author-created macros would have to cooperate very carefully to ensure execution of macros produces correct tagging of the resulting documents’ content. That “orchestration” would have to be reliable—no matter how authors choose to combine and use the features, commands and functionality of LaTeX, its package system and the power of TeX macros.
The needs of authors
For most people, LaTeX is just a tool which lets you create beautifully typeset documents with the freedom to pick and choose packages to help you achieve that. The vast majority of LaTeX authors simply want their documents “to work”: to typeset without error so they can submit their thesis, article, report or finish that long-awaited book. Not unreasonably, users of LaTeX expect their chosen collection of LaTeX packages to coexist peacefully, seamlessly and transparently interoperating to provide the commands and features necessary to produce their documents. Those same desires are likely to be found when faced with the requirement to produce tagged PDF from LaTeX: it should “just work”, transparently and with minimal author intervention. Unfortunately, we are some distance from the experience of “Hey Presto! tagging just happens no matter what weird stuff I do”. Coupling the technical requirements of accessibility plus tagged PDF with LaTeX and authorship freedom is inherently complex and, perhaps, it may be unavoidable that some form of “author discipline” might be required if the technical challenges are to become amenable to practical implementation and resolution.
A separate, but related, issue is that incorrect tagging may have no visual impact on the final PDF: visually, it may look perfect and it will likely print without issues too, but, unknown to the author, the tagging may be “broken”, only to be discovered through subsequent failure of PDF/A compliance/validation checks and/or further practical testing via accessibility software such as screen readers.
PDF files produced on Overleaf
Overleaf provides its user community with a browser-based LaTeX editor together with project and document management tools which facilitate collaborative authoring—all built on top of a standard TeX Live installation. In effect, Overleaf allows users to “run LaTeX at a distance” via a web browser, providing a layer of insulation from the complexities of managing and maintaining a full TeX Live system.
A consequence of Overleaf’s use of a standard TeX/LaTeX installation is that PDFs produced from LaTeX code written in Overleaf’s editor are created using the exact same technologies present in any other, same-version, TeX Live installation—including setups users have installed on their local devices. The only difference is that the TeX engines which compile and process Overleaf’s LaTeX code run on remote servers, not on local machines. Overleaf does linearize the TeX-generated PDF for efficient download/display in a browser but that process is unrelated to accessibility of the PDF content itself.
Production of accessible PDFs via Overleaf is reliant upon the capabilities and features built into standard TeX engines together with the availability of suitable LaTeX macro packages which users can deploy as part of their document. LaTeX documents created using Overleaf have to remain compatible with other TeX and LaTeX installations because users frequently need to export their LaTeX project from Overleaf for submission to a wide range of publisher journal systems. Introducing Overleaf-specific features into its LaTeX documents, or the underlying TeX engines, would seriously inhibit users’ freedom to use their work elsewhere.
Overleaf recognize and support the need for fully accessible PDFs generated from TeX/LaTeX authoring systems: we invest time in researching accessibility issues, exploring the latest developments in TeX engines and experimental LaTeX packages which support tagged PDF. Ultimately, at the time of writing, there is no “out of the box” solution that LaTeX authors can use (via \usepackage) to seamlessly and transparently generate fully accessible and PDF/UA-compliant PDFs from generic LaTeX documents. When those solutions are available through TeX Live updates they will, of course, become available to the Overleaf user community.
Some LaTeX packages for exploring tagging and accessibility
For many people, tex.stackexchage is the first port of call for help with TeX, LaTeX or ConTeXt. It’s an amazing resource and has many questions on the topic of accessibility and the production of accessible PDFs via LaTeX. If you read and browse these questions, and the ensuing stream of answers and comments, only one conclusion is inevitable: at the present time there is no full, production-level solution to automatically create fully accessible, standards-compliant, tagged PDFs from every type of LaTeX document. However, there are some packages which support tagging—though, perhaps, within a restricted range of use-cases and document types. The following list is provided for readers wishing to explore LaTeX-based PDF tagging:
tagpdfpackage (Ulrike Fischer): highly capable package designed for experimenting with PDF tagging. Supports pdfTeX and LuaTeX and provides extremely useful and interesting documention which contains some excellent notes on the technical challenges of creating tagged PDFs via TeX engines; it is highly a recommended read for anyone interested to better understand the issues involved. Focus of future direction likely to be LuaTeX.axessibilitypackage (Boris Doubrov and University of Turin): providing access to formulas in PDF files by assistive technologies.accessibilitypackage (Andy Clifton): creates tagged and structured PDF files. The CTAN notes state that this package is “Aimed at users of the KOMA-Script document classes”.accsupppackage (Heiko Oberdiek): experimental package to provide better accessibility support for PDF files.
A further noteworthy reference is a 2018 paper Implementing PDF standards for Mathematical Publishing by Dr Ross Moore of the Department of Mathematics, Macquarie University. In that paper Dr Moore includes a short outline of the challenges of tagging of PDFs in LaTeX:
“The main source of difficulty lies in the way that different environments can interact with each other. There are many situations in LaTeX where one environment or structure is not really completed until the next has begun. So it is not just a matter of wrapping start and finish tags around every piece of supplied content. Instead one needs to understand the subtleties of how different environments and other structures actually start and finish, within the context established by surrounding material.”
Dr Moore is also the current maintainer of the pdfx package and an expert and pioneer of tagged PDF using TeX/LaTeX. His work is well worth searching for—including this video on YouTube which provides interesting insights:
Note on the pdfx package
The pdfx package (Ross Moore et al) provides excellent support for PDF/A-1|2|3b (archiving), and other options, but does not yet produce tagged PDF.